

As the line between the digital and physical worlds blurs, people are demanding new ways to interact with digital technology without being bounded by small touch screens and laptops. Gartner predicts that by 2020, about 30% of all web-browsing sessions will take place without the use of a screen.
A huge driving force behind this trend has been the rapid adoption of voice and audio as input and feedback for personal assistants, cars, phones, and more. But audio interfaces alone miss a lot of context—they’re like talking to a friend on the other side of a wall. To enable much more intuitive user experiences and help launch digital interactions forward, we are combining voice with other technologies like spatial awareness, 3D mapping, person identification, and gesture recognition.

Imagine being able to say “Ok Google, turn off that light” while pointing at the light you want turned off, or ask “Alexa, where did I leave my keys?” or even say “Siri, bring this box to Steve.” We are developing a robot that enables these kinds of experiences. The big idea is to interact with the digital world like you would with a friend, referencing objects and locations around you in an entirely new way that is much less bounded than the pure audio or one-way display experiences possible with today’s virtual assistants.
Enabling Technologies
Behind such a natural interaction, it’s easy to forget that there is a lot of custom, cutting edge engineering in the background making it possible. Here are some of the technologies we’re integrating to enable this more natural experience.
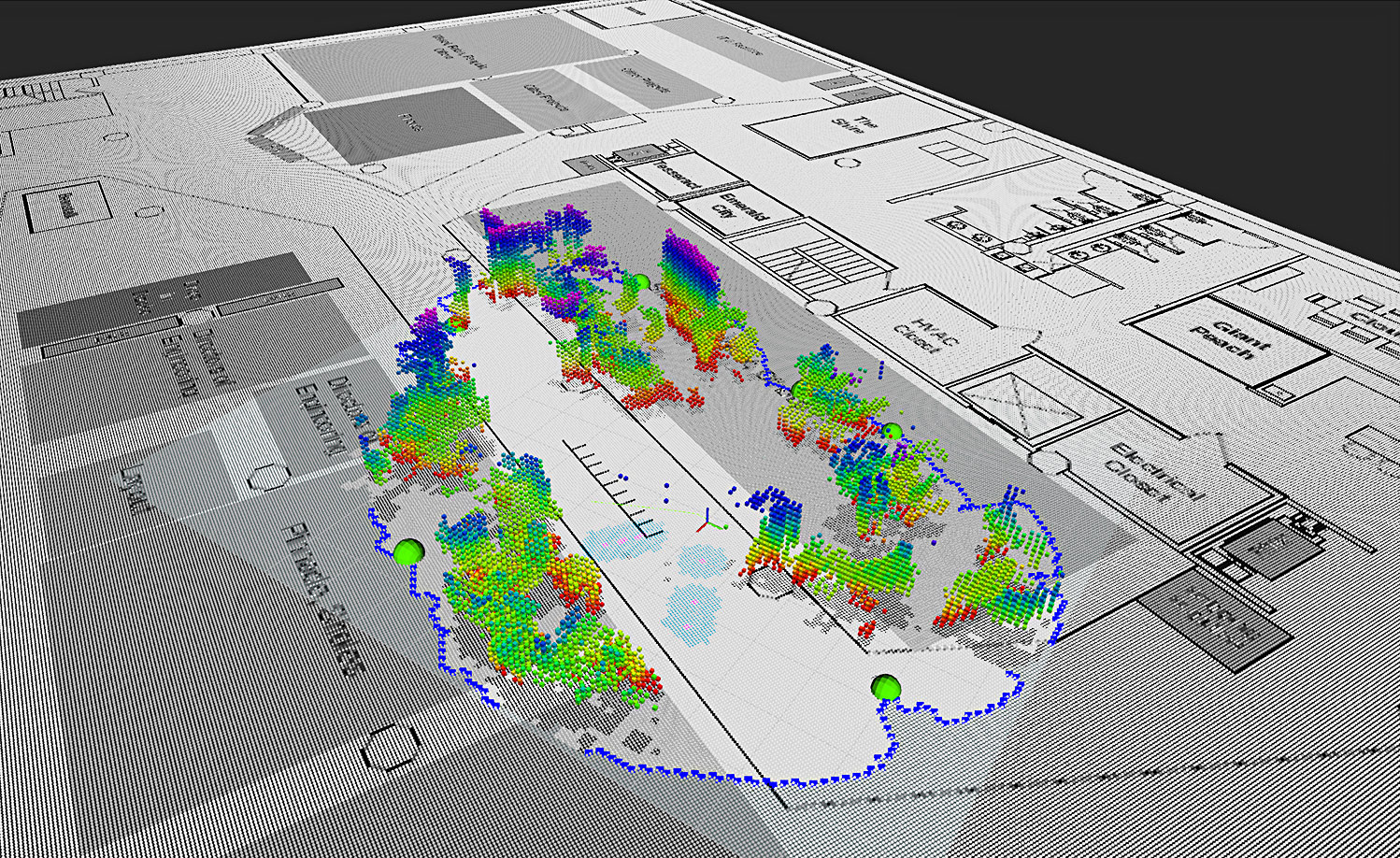
Autonomous Robotic 3-D Spatial Mapping
Our robot uses Simultaneous Localization and Mapping (SLAM) to understand the world around it. It autonomously explores physical spaces—offices, homes, factory floors, venues, and other places of interest, creating a persistent 3D map of the walls and floors using depth sensors, video cameras, and onboard processing. It’s aware of its own location and where it’s been, thanks to visual odometry technology, which tracks and records its position and orientation in 3D space. This tech also lets the robot know where to explore next and update its map when transient objects move out of the way.

Real-Time, Vision-Based Face, Object, and Gesture Recognition
Using the same cameras and onboard processing that enable our mapping and navigation, the robot also recognizes people, objects, and gestures using neural network-based machine vision. When possible, we train our system using existing public datasets for things like skeletal gesture mapping and facial recognition, but we can also collect and synthetically generate our own training data when needed.

Voice Recognition
Voice recognition technology is all around us these days, but it still isn’t necessarily easy to implement well for novel use cases. We want our robot to perform effectively while driving around and in noisy environments, so mechanical isolation of the microphone array is critical, as is noise and echo cancellation. To maximize system accuracy, we’re using a state-of-the-art phased array microphone technology along with modern speech recognition software. We’ve also combined the audio sensing with our vision-based human recognition engine, so we not only know what is being said, but who is saying it, and where they are in relation to the robot.

Artificial Intelligence and Sensor Fusion Tie it all Together
Our AI engine enables the robot to infer your intent by combining voice commands with gestures and its 3D map. It’s this combination of disparate datasets that enables such a natural user experience. When the robot sees you point at a light, for example, it knows roughly the orientation and position of your arm relative to its own position and orientation, and can use that to triangulate where on its spatial map you are pointing. Because it has mapped the room, it knows which controllable objects are located in that direction, and because it has heard you say “turn on that light,” it knows that the light is the object you’re asking to control.
Looking Forward
We’re excited to push digital-physical interfaces even further forward, allowing us to look up from our screens and interact with the world in a more natural way while still benefiting from the huge ongoing advances in digital technology. Check out some of the articles and case studies below or get in touch to talk about how we could work together to make magical experiences a reality.